


AI is eating the world, and data is its favorite meal. Nearly 90% of the world’s data was created in just the last few years, and every flashy AI tool out there runs on one thing: clean, reliable data. The catch? Most companies are sitting on mountains of messy logs, spreadsheets, and half-documented APIs that are nowhere near “AI-ready.”
That’s where the AI-driven data pipeline steps up — the behind-the-scenes plumbing that turns raw, chaotic data into something your models can actually make sense of. It’s the missing link between your scattered data sources and your next AI win.
Think of it as ETL 2.0: still about moving and transforming data, but now smarter, faster, and self-aware. In this guide, we’ll break down how integrating AI into your pipelines actually works, the big wins companies are seeing, and the hard lessons learned along the way.
Why AI in Data Pipelines Matters
In traditional data architectures, pipelines were the arteries of an organization designed to move data from one system to another, often in nightly batches. They served the analytics layer but rarely went beyond historical reporting.
AI integration changes that paradigm. It transforms the pipeline from a passive data mover into an active intelligence layer. Instead of simply showing what happened yesterday, AI-enhanced pipelines can anticipate what might happen tomorrow and suggest how to respond.
There are a few key reasons this shift matters:
- From hindsight to foresight. Conventional dashboards describe the past. AI pipelines, by contrast, deliver predictive and prescriptive insights in near real-time.
- Scalability and complexity. Modern data sources are not just structured tables but also images, logs, IoT streams, and unstructured text. AI enables these diverse sources to be processed, understood, and utilized more effectively.
- Democratization of insights. With intelligent automation, data pipelines can now be designed or adjusted with far less technical effort. Non-technical teams can request insights or transformations using natural-language tools, while AI systems handle the heavy lifting behind the scenes.
- Smarter operations. Intelligent pipelines can self-monitor, detect anomalies, and optimize data flow, reducing downtime and maintenance costs.
In short, AI doesn’t replace the data pipeline. It amplifies it.
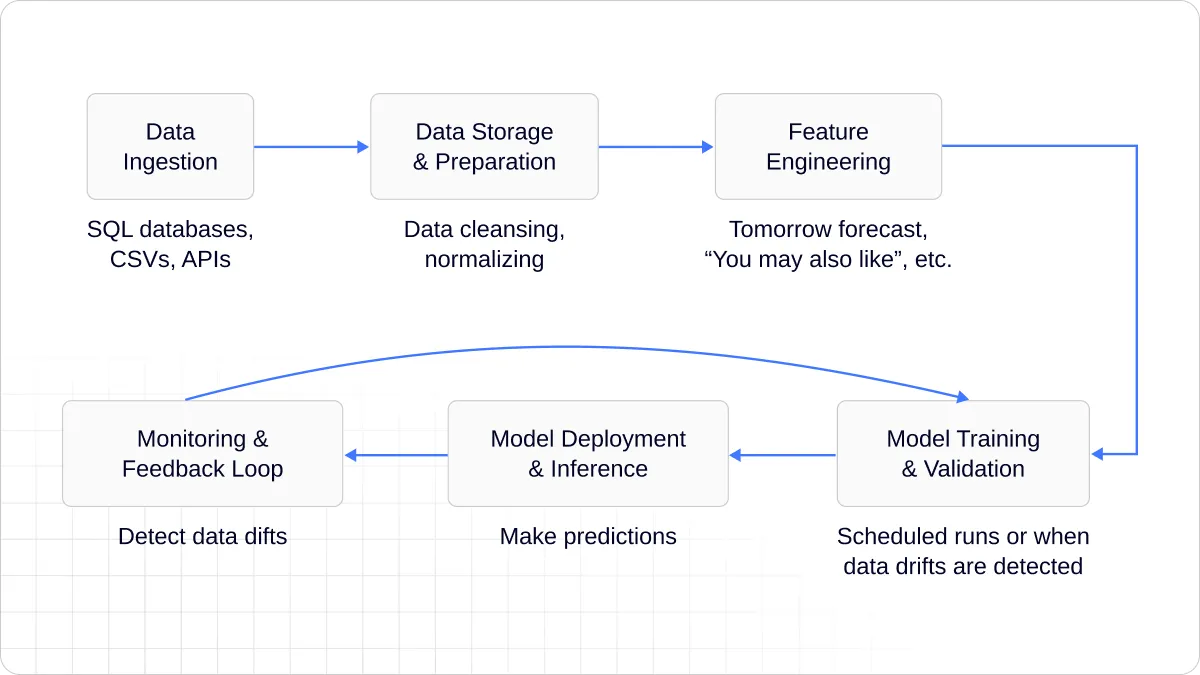
Anatomy of an AI-Enabled Pipeline
At its core, an AI-integrated data pipeline still follows familiar stages — but each stage is now enhanced with intelligence and automation.
- Data Ingestion. Data from multiple, disparate sources is collected continuously, from databases, APIs, cloud platforms, sensors, and streaming applications.
- Data Preparation. Instead of static cleaning and transformation rules, AI models can automatically detect missing values, outliers, and inconsistencies, adapting their transformations based on evolving data patterns.
- Feature Engineering. This is where AI adds true value, identifying correlations, generating new variables, and uncovering relationships that manual analysis might miss.
- Model Training and Validation. The pipeline can incorporate machine learning stages, where models are trained, validated, and tuned automatically as new data flows in.
- Deployment and Inference. Once trained, models are deployed back into the pipeline, enabling live predictions and intelligent decision-making embedded directly into business processes.
- Monitoring and Feedback. Intelligent pipelines continuously monitor their own performance, tracking data drift, model degradation, and operational anomalies and triggering retraining or alerts as needed.
7 Ways AI Data Pipelines Transform the Way You Work with Data
Let’s be honest! The magic of an AI data pipeline isn’t in the architecture diagrams or the buzzwords. It’s in what it frees you from (the endless grind) and what it unlocks (actual wins). So, let’s skip the theory and talk about how this really changes your day-to-day with examples you’ve probably lived through yourself.
1. Automate the Repetitive Work
We’ve all been there — another failed job because someone uploaded a bad CSV or an API call timed out. Sure, you can fix it, but it’s never just once.
AI-powered pipelines handle this differently. They don’t just react; they learn. They can detect strange patterns, spot data drift, and fix issues before they snowball. The result? Fewer late nights and less firefighting.
Instead of manually creating endless validation rules, AI systems learn what “normal” data looks like and flag anything unusual automatically.
Example: Instead of scripting dozens of checks for missing readings, an AI-enabled process identifies what typical data should look like and alerts you when something doesn’t add up.
2. Produce Cleaner, More Reliable Data
Classic ETL tools can tell you when something’s missing or malformed. AI data pipelines go a step further. They fix issues intelligently.
They don’t just highlight missing fields; they can fill in blanks using learned historical trends or statistical inference, keeping downstream systems consistent and reliable.
Example: Dealing with a dashboard full of missing records makes reporting almost impossible. With AI-driven imputation, the system could accurately estimate the missing values, keeping analytics smooth and trustworthy.
3. Deliver Models and Value Faster
Old-school data workflows were linear: clean, load, visualize, repeat. AI pipelines make that process continuous and connected. Data doesn’t just end up in dashboards, it flows straight into model training, validation, and deployment.
You can also integrate tools to manage experiments and track model versions, keeping everything traceable and consistent.
Example: Instead of waiting weeks to see results from a new KPI report, you can roll out a churn prediction model in days. Streamlined data flow equals faster outcomes.
4. Scale Without Adding More People
Scaling traditional ETL pipelines can feel like trying to stretch a rubber band. It works until it doesn’t. With AI-built pipelines, growth doesn’t automatically mean more hands on deck. They’re designed to scale horizontally, handling bigger data volumes and new sources automatically.
You still set the direction, but the system handles much of the heavy lifting. That means your team can stay lean without sacrificing performance.
Example: When integrating IoT data streams for a utilities project, the automated pipeline manages ingestion and transformation seamlessly. All you have to do is fine-tune exceptions, not rewrite the process.
5. Unlock Real-Time Insights
Traditional ETL runs on batch jobs (data moves overnight; insights arrive tomorrow). AI-driven pipelines shift that to real time. Combined with streaming technologies like Kafka or live model serving via KFServing, predictions happen on the fly.
6. Turn Data Into Real-Time Business Impact
Dashboards explain what happened yesterday. AI pipelines predict what’s coming tomorrow and help you act on it now. That’s the real shift: from reactive reporting to proactive strategy.
By embedding ML directly into data warehouses (using tools like BigQuery ML or Snowflake ML), companies can generate predictions without spinning up a separate workflow.
Success Stories and Real-World Impact
Organizations that have successfully integrated AI into their data pipelines report measurable benefits:
Real-time recommendations
Retail and e-commerce platforms are moving beyond static product suggestions. By analyzing user behavior in real time, AI-driven pipelines can recommend products or content the moment interest is detected — not hours later.
Proactive fraud detection
In finance, AI-enabled pipelines monitor transactions continuously, spotting unusual patterns and blocking suspicious activity instantly.
Operational optimization
In manufacturing and logistics, intelligent data pipelines combine sensor data and predictive models to forecast equipment failures or supply chain delays before they occur.
Faster integration
AI can automatically generate transformation logic, schema mappings, and data validation steps, reducing the manual workload for data engineers and shortening time-to-value.
Empowered business teams
Non-technical users can now request or modify data flows through conversational interfaces or low-code environments, supported by AI that interprets intent and builds the required logic automatically.
The Challenges of AI Integration
Sure, AI makes data pipelines smarter. But it also makes them trickier. The road to automation isn’t a straight line. Here’s where most teams hit bumps, and what they’re doing to smooth the ride.
1. Data Silos and Fragmentation
Many enterprises still operate with disconnected systems with each department holding its own version of the truth. When data is scattered across incompatible platforms, building a unified, AI-ready pipeline becomes difficult.
Solution: Invest in connectors and shared metadata management. Establish governance frameworks that promote data standardization and interoperability across teams.
2. Data Quality and Complexity
AI thrives on clean, consistent, and complete data. Unfortunately, real-world data rarely meets that standard. Inaccurate or biased inputs can distort models and produce misleading results at scale.
Solution: Incorporate data validation, anomaly detection, and cleansing steps directly into the pipeline. Use AI not only to analyze data but also to improve its quality through pattern recognition and automated correction.
3. Scalability and Real-Time Performance
Traditional ETL processes often struggle with high-velocity or streaming data. AI pipelines must handle continuous ingestion, large model training workloads, and real-time inference, all without bottlenecks.
Solution: Adopt cloud-native, elastic architectures that scale automatically with demand. Leverage containerization and orchestration tools to manage compute resources efficiently.
4. Collaboration and Culture
AI integration changes team dynamics. Data engineers, scientists, and operations specialists must collaborate more closely than ever before. The traditional separation between “data prep” and “modeling” disappears.
Solution: Foster cross-functional teams and shared accountability. Encourage knowledge sharing between data engineers and AI specialists. Adopt MLOps and DevOps principles to align development, deployment, and monitoring.
5. Governance, Ethics, and Security
With great automation comes greater risk. AI models embedded in pipelines can introduce bias, make opaque decisions, or expose sensitive data. Without oversight, trust in AI-generated insights quickly erodes.
Solution: Build transparency into every layer of the pipeline. Implement data lineage tracking, model explainability, and audit trails. Enforce access controls and compliance checks for all data flows.
6. Model Drift and Maintenance
Models don’t stay accurate forever. As business conditions and data patterns evolve, AI models can degrade, making predictions unreliable.
Solution: Monitor models for drift and performance decay. Automate retraining cycles and feedback loops, so the pipeline stays aligned with current realities.
Best Practices for Building Intelligent Pipelines
Based on lessons from early adopters, several best practices consistently emerge:
- Start with strong foundations. Before layering AI, ensure that data ingestion, transformation, and storage are reliable, well-documented, and consistent.
- Embed intelligence gradually. Integrate AI components step by step — start with automation of data cleaning or transformation before moving into predictive modeling.
- Focus on clear business outcomes. Every AI feature should serve a measurable purpose, whether it’s improving customer experience, operational efficiency, or forecasting accuracy.
- Adopt MLOps frameworks. Treat models like software — with version control, testing, deployment pipelines, and rollback capabilities.
- Build transparency and governance early. Establish monitoring, logging, and explainability from the start rather than as an afterthought.
- Empower your people. Provide upskilling and tools so that teams understand not just how to use AI, but when and why.
- Monitor continuously. Implement performance dashboards for both data quality and model accuracy. Treat your pipeline as an evolving system, not a static project.
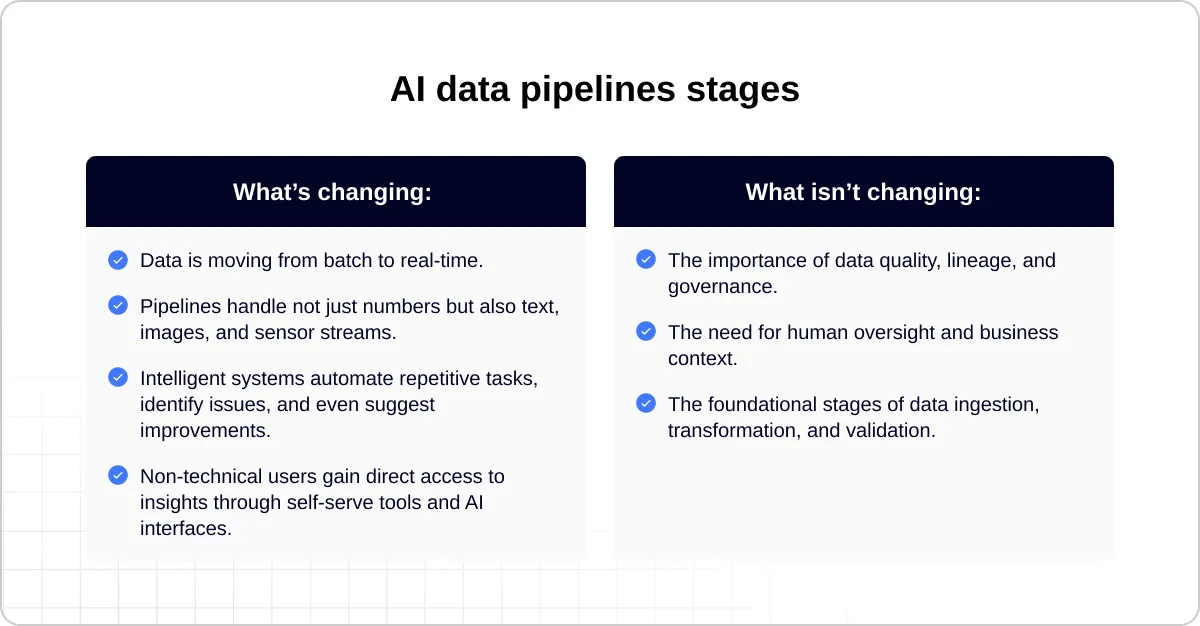
What’s Changing and What Isn’t
The Road Ahead
As AI continues to mature, data pipelines will evolve into adaptive, self-optimizing systems that require minimal human intervention. In the near future, pipelines may:
- Automatically detect and connect new data sources.
- Learn from historical transformations to optimize themselves.
- Predict and prevent failures before they happen.
- Explain their outputs and decisions in human-readable form.
The ultimate goal is not just automation for its own sake but intelligence at every step, where data pipelines sense, learn, and act as integral parts of a business’s decision fabric.
Start Innovating Now
If your data’s ready to evolve, so is your business. BlueCloud helps companies weave AI into their data pipelines, connecting systems, automating the heavy lifting, and setting the stage for an AI-ready future. Talk to us about where you want to take your data next.


